
매년 혁신 기술을 선정하는 MIT Tech Review는 강화학습(Reinforcement Learning)을 2017년 10대 미래 혁신 기술(Breakthrough Technology) 중 하나로 선정했습니다. 강화학습은 반복 학습을 통해 인공지능이 문제를 해결하는 방법을 스스로 터득한다는 점에서 기존 인공지능의 구현 방식과 전혀 다릅니다.
기존 기계학습 기반의 인공지능은 목표 달성 과정을 전문가가 일일이 모델링하고 구현해야 했지만, 강화학습 기반의 인공지능은 스스로 현재의 환경을 인식하고 행동하며 목표를 달성해 나갈 수 있습니다.
게다가 강화학습의 방식은 범용적으로 활용할 수 있어, 새로운 환경에서 학습만 반복하면, 하나의 알고리즘을 가지고 다양한 환경에 적용 가능한 인공지능을 구현해 낼 수 있습니다. 일반인들에게 인공지능의 혁신을 알렸던 알파고(AlphaGo)의 핵심 기술이 바로, 강화학습 기반이었습니다.

알파고 이후 강화학습을 적용한 인공지능 연구가 본격화되면서 바둑을 넘어 다양한 분야에 강화학습이 적용되며 혁신을 만들어 내고 있습니다. 하지만, 강화학습 기반 인공지능의 발전은 그 적용 분야가 게임 환경과 같은 2차원 가상환경에서의 지능 구현이었습니다. 때문에 실제 인간의 환경과는 큰 차이가 있어, 강화학습을 현실 세계의 문제에 적용하는 것에는 한계가 있었습니다.
이러한 한계를 극복하기 위해 인공지능 분야의 주요 선도 연구 단체, 기업들은 3차원 환경 혹은 실제 물리적 환경에서 강화학습을 적용하기 위한 선행 연구에 집중하기 시작했습니다.
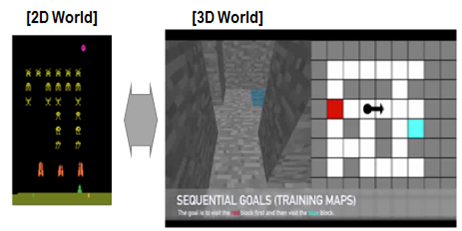
l 3차원 환경의 어려움
따라서 주요 연구자들은 기존 강화학습에 새로운 기술을 접목시키며, 3차원 환경에 강화학습을 구현하고 있습니다. 인공신경망 내에 과거의 경험을 기억할 수 있는 별도의 메모리를 설계 하거나 학습을 통해 축적된 지식을 일반화해 새로운 환경(Unseen Environments)에 적용1하기도 합니다. Open AI는 3차원 환경에서 강화학습 알고리즘을 검증 가능한 Minecraft, Doom과 같은 3차원의 게임 환경을 공개해 개발자•연구자들이 활용하게 하고 있습니다.
또한, 동일한 환경에서 개발자들이 서로의 알고리즘 성능을 경쟁하며 발전할 수 있도록 각종 경진대회가 진행 중입니다. Doom 게임의 경우 Vizdoom2이라는 대회에서 개발자들은 학습 시간을 최소화하거나 최소 시간에 목표 도달, 고득점 달성 등과 같은 다양한 목적에 대해 서로 경쟁하며 알고리즘을 고도화시킵니다.
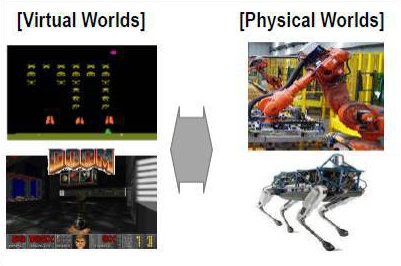
l 물리적 환경을 반영한 알고리즘 구현
따라서, 한계를 극복하기 위한 연구들이 빠르게 진행되고 있습니다. 캐나다 UBC 연구팀은 가상의 캐릭터에 실제 물리 환경을 최대한 반영하여 모델링 후 강화학습을 적용3했는데요.
아래 그림과 같이 강아지 모양의 동물 캐릭터가 스스로 달리며 오르막을 오르거나 장애물을 통과하는 방법을 학습하는 과정을 강화학습으로 구현할 때, 강아지 모양의 대상을 단순히 하나의 객체로 처리하지 않습니다. 실제 동물의 몸이 수많은 관절로 연결된 것과 같이 가상환경의 대상을 매우 정교하게 모델링한 것인데요.
논문에 따르면 달리기를 학습하는 과정에서 매 순간 약 300개 이상의 물리적 변수들이 종합적으로 분석되고 약 30만 번의 반복 학습을 통해 스스로 뛰는 방법을 터득하게 했습니다.

l 물리적 환경을 반영한 알고리즘 구현
딥마인드 또한 최근 세 편의 논문4을 연이어 발표하며 현실 환경을 정교하게 반영한 강화학습 알고리즘을 구현했습니다.
아래 그림과 같이 사람과 같은 모양의 캐릭터가 스스로 걷고, 뛰는 방법을 강화학습을 적용해 스스로 터득하게 한 것인데요. 사람을 최대한 묘사해 머리, 몸통, 팔, 다리로 캐릭터를 구성했고, 신체의 각 부분의 관절까지 반영하여 움직임에 따른 힘의 분배와 상관관계가 고려되었습니다.
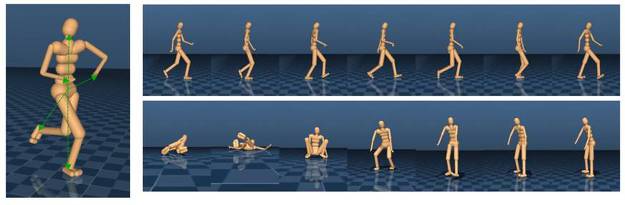
l 강화학습 기반의 사람의 동작 학습 알고리즘
이러한 복잡한 물리법칙을 고려해 만든 실제 로봇에 강화학습을 적용하기도 합니다. SnakeBot5, Pingpong Robot6등과 같은 로봇 연구에서는 로봇이 스스로 반복 학습을 통해 장애물을 넘거나 탁구 치는 방법을 익혀갑니다. 또한, UC 버클리대의 세르게이 레빈교수팀은 강화학습을 적용해 로봇이 스스로 학습해 물체를 집어 올리거나7, 문을 열어가는 과정8을 터득시켰습니다.
다양한 모양의 물체에 대해 약 80만 번의 시행착오를 반복하며 물체를 집는 방향과 힘을 조절합니다. 이때, 한 대의 로봇이 아닌 약 6~14대의 로봇이 동시에 학습을 수행하고 각 로봇의 학습 과정이 서로 공유되어 모든 로봇이 같은 실수를 반복하지 않고 매우 빠르게 지능을 발전시킵니다.

l 강화학습 알고리즘의 로봇 적용
딥마인드의 연구로 본격화된 강화학습 알고리즘의 연구는 약 2년 만에 엄청난 발전을 이루고 있습니다. 간단한 2차원 게임 환경을 넘어서 3차원, 물리 환경에 기반을 둔 연구들이 빠르게 진행되며 현실 세계에 강화학습 기반의 인공지능 구현을 앞당기고 있죠. 실제로 주요 기업들의 연구소에서는 강화학습을 실제 제품, 서비스에 적용하려는 연구, 개발이 활발히 진행 중입니다.
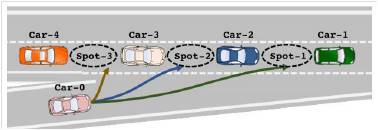
l 강화학습 기반의 지능형•자율 주행 기능 연구
실제 주요 자동차 OEM의 선행연구 기관에서는 강화학습을 적용한 지능형•자율 주행 기능을 구현하려 했습니다. 자동차가 램프 진입 시 옆 차선에서 진행 중인 다른 차들의 속도, 거리 등을 고려해 진입 위치를 결정하는 것입니다.
사람의 경우에도 초보 운전 시 매우 어려운 과정이지만 수 많은 반복 경험을 통해 직관적으로 판단하여 진입 위치를 결정하고 속도를 조절해 진입하는 것과 마찬가지로 강화학습을 통해 인공지능이 스스로 상황을 판단해 매 순간 최적의 결정을 내릴 수 있도록 합니다.
이러한 과정을 기존 모델링 기반의 기계학습 방식으로 완벽하게 구현하기는 매우 어렵습니다. 하지만, 강화학습에 기반한 충분한 학습 과정만 반복할 수 있다면 인간 수준의 성능으로 구현이 가능해 질 수도 있습니다.
자율 주행 외에도 스마트 팩토리 내 다양한 제조 공정, 로봇 등에 강화학습 기반의 인공지능이 앞으로 빠르게 적용될 것으로 전망되며, 이렇게 되면 현실 세계의 인간처럼 학습하는 기계가 인간과 협력 혹은 경쟁하는 시대가 도래할 것으로 예상됩니다.
글 | 이승훈 책임연구원(shlee@lgeri.com) | LG경제연구원
* 해당 콘텐츠는 저작권법에 의하여 보호받는 저작물로 LG CNS 블로그에 저작권이 있습니다.
* 해당 콘텐츠는 사전 동의 없이 2차 가공 및 영리적인 이용을 금하고 있습니다.
- J. Oh, et al., Control of Memory, Active Perception, and Action in 3D world, ICML 2016 [본문으로]
- http://vizdoom.cs.put.edu.pl/competition-cig-2016 [본문으로]
- X. Peng, et al., Terrain-Adaptive Locomotion Skills Using Deep Reinforcement Learning, SIGGRAPH 2016 [본문으로]
- N. Heess, et al., Emergence of Locomotion Behaviours in Rich Environments, 2017. 7 J. Merel, et al., Learning human behaviors from motion capture by adversarial imitation, 2017. 7 Z. Wang, et al., Robust Imitation of Diverse Behaviors 2017. 7 [본문으로]
- M. Tesch, et al, Learning Stochastic Binary Tasks using Bayesian, Optimization with Shared Task Knowledge, ICML 2013 [본문으로]
- Mülling, Katharina, et al. "Learning to select and generalize striking movements in robot table tennis." The International Journal of Robotics Research, 2013; [본문으로]
- S. Gu, et al, Learning Hand-Eye Coordination for Robotic Grasping with Deep Learning and Large-Scale Data Collection, IJRR, 2017 [본문으로]
- S. Gu, et al., Deep Reinforcement Learning for Robotic Manipulation with Asynchronous Off-Policy Updates. ICRA 2017 [본문으로]