
"기존 CPU 한계, 이 '이론'이면 뒤집을 수 있습니다"
[지디넷코리아]
"기존 CPU는 순차 처리 방식에 특화돼 있어, AI 산업이 필요로 하는 병렬 처리를 제대로 하지 못한다는 한계가 있었죠. 이를 뒤집고 CPU의 병렬 처리를 구현해낼 수 있는 기술이 바로 '한 주기 이론'입니다. 해당 이론을 입증할 첫 번째 컴파일러가 이달 완성됩니다."
이종열 전북대학교 전자공학부 교수는 최근 전북 전주시에 위치한 전북대학교 제7공학관에서 기자와 만나 한 주기 이론의 개발 현황 및 향후 계획에 대해 밝혔다.
이 교수는 전북대학교 전자공학부에서 SoC(시스템온칩) 디자인을 연구하고 있다. 카이스트에서 공학 석사·박사 과정을 밟은 뒤, 하이닉스반도체(현 SK하이닉스) 선임연구원을 거쳐 전북대학교 교수로 재직 중이다.
현재 PC·스마트폰 등에 필수적으로 탑재되는 CPU(중앙처리장치)는 순차 처리 방식에 특화된 구조를 가지고 있다. 순차 처리 방식이란 CPU 내에서 연산을 담당하는 코어가 한 번에 한 가지의 명령어를 처리하는 것을 뜻한다. 이를 통해 CPU는 데이터 수집, 분석, 저장 등의 과정을 순차적으로 진행한다.
다만 순차 처리 방식은 방대한 양의 데이터를 반복적으로 연산해야 하는 AI 산업에는 적합하지 않다. CPU 내 코어 수를 늘려 아무리 처리 속도를 향상시켜도, 하나의 작업이 끝나기 전까지 다음 작업을 수행할 수 없기 때문이다. 때문에 업계는 복수의 명령어를 동시에 처리하는 병렬 처리 방식의 GPU를 AI 서버에 탑재하고 있다.
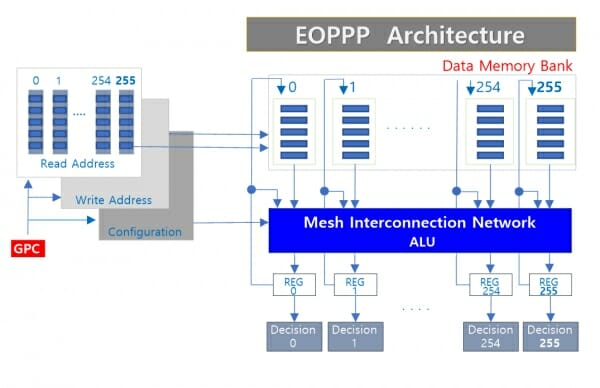
이 교수는 이러한 CPU의 한계를 뒤집을 수 있는 방안으로 한 주기 이론(EOPPP; Every One Period Parallel Processor)에 주목한다.
EOPPP는 CPU 내의 각 코어를 연결하고 자유롭게 데이터를 공유할 수 있도록 하는 '메시 네트워크'를 두는 것이 핵심이다. 각 CPU 코어는 연산 전에 미리 배분 및 저장해 둔 데이터를 한 주기에 동시에 처리하고, 이후 처리된 데이터를 메시 네트워크로 보낸다.
메시 네트워크는 송신된 데이터를 정렬해 저장하고, 이 결과값을 다시 각 코어로 보내 다음 한 주기에 사용할 수 있도록 한다. 이러한 구조를 활용하면 CPU에서도 GPU와 같은 병렬 방식을 구현할 수 있게 된다. 즉 CPU의 기능에 GPU 하드웨어 구조를 갖춘 새로운 프로세서인 셈이다.
이 교수는 "기존에도 인텔 등이 CPU에 SIMD(하나의 명령어로 여러 데이터를 연산)를 적용해 병렬 처리를 일부분 구현하고 있다"며 "그러나 EOPPP는 이와는 완전히 다른 개념으로 SIMD와 MIMD(복수의 명령어로 복수의 데이터를 연산) 모두 구현이 가능하다"고 강조했다.
EOPPP는 지난 2018년 설립된 국내 팹리스 스타트업 모르미의 이준범 대표가 정립한 이론이다. 이준범 모르미 대표는 현재 EOPPP 기반의 아키텍처·기계어 등을 특허로 등록했으며, 32코어 FPGA(필드프로그래머블게이트어레이) 샘플을 제작해 기존 CPU 대비 특정 분야에서 성능이 최대 10배 높음을 검증했다.
이 교수는 "이준범 대표를 만나 한 주기 이론에 대한 설명을 듣고, 이를 반도체 산업에 실제로 적용할 수 있겠다는 결론을 내렸다"며 "이후 모르미와 협력해 EOPPP 검증을 위한 컴파일러를 만드는 작업에 전념해왔다"고 설명했다.
컴파일러는 개발자가 사용하는 프로그래밍 언어를 컴퓨터가 이해할 수 있는 기계어로 바꿔주는 번역 프로그램이다. 이 컴파일러가 있어야 EOPPP 기반의 하드웨어 내에서 실제 데이터를 배분하고, 저장해주는 등 설정값을 수월하게 구현할 수 있다. 컴파일러가 없다면 개발자가 기계어를 직접 일일이 입력해야 하므로 활용성이 크게 떨어진다.
EOPPP용 컴파일러의 첫 버전은 이달 중 완성될 예정이다. 그동안에는 기계어를 직접 입력해 하드웨어 샘플을 시현했으나, 이번 컴파일러 개발로 EOPPP의 상용화 가능성을 입증할 수 있는 초석이 마련됐다는 게 이종열 교수의 설명이다.
이 교수는 "첫 컴파일러가 개발되면서 EOPPP 기반 CPU를 시현하기 위한 하드웨어, 소프트웨어적 준비가 모두 완료됐다"며 "앞으로 다양한 테스트를 거쳐 컴파일러 완성도를 높이고, 이를 기반으로 연말까지 학계에 논문을 제출할 계획"이라고 말했다.
이종열 교수는 EOPPP가 적용된 CPU가 상용화되는 경우, 반도체 업계에 상당한 변화를 가져올 수 있다고 기대하고 있다.
먼저 CPU 자체의 성능 극대화다. 기존 CPU에서 병렬 처리가 가능한 영역은 5% 수준에 불과한 것으로 알려져 있다. 때문에 코어 수를 아무리 늘려도 이론상 성능을 2배까지 높이는 게 불가능하다는 '암달의 법칙'의 지배를 받아왔다. 반면 EOPPP 기반 CPU는 완전한 병렬 처리 구조를 갖추고 있어, 코어 수 증가에 따른 성능 확대 제약에서 자유롭다.
이 교수는 "계산상으로 EOPPP 기반 CPU는 코어 수가 배로 증가하면 그만큼 성능도 배로 증가할 수 있다"며 "물론 실제 하드웨어 칩 제작에 이를 그대로 적용할 수는 없지만, 기존 CPU가 하지 못한 병렬 처리를 가능케 한다는 점에서 큰 의미가 있다"고 설명했다.
AI 산업에서도 변혁을 일으킬 수 있다. 현재 AI용 서버는 엔비디아의 고성능 GPU가 시장을 주도하고 있다. 이에 대응해 테슬라, 구글, 마이크로소프트 등이 앞다퉈 NPU(신경망처리장치)를 개발해왔다. 국내 복수의 스타트업도 대형 업체가 시장을 선점한 CPU·GPU 대신 새로운 시장인 NPU 개발에 뛰어든 바 있다.
NPU는 컴퓨터가 데이터를 학습하고 자동으로 결과를 개선하는 머신러닝(ML)에 특화된 칩이다. GPU보다 데이터 연산 효율성이 높다. 그러나 동시에 NPU는 특정 기능에 집중돼 있어, CPU·GPU와 같은 범용성이 부족하다. 아무리 뛰어난 성능의 NPU가 개발돼도 GPU 시장을 완전히 대체할 수 없다는 분석이 나오는 이유다.
이러한 상황에서 EOPPP 기반 CPU는 개발 분야에서 GPU를 대체하는 기회를 잡을 수 있다. AI 반도체는 로직반도체인 CPU·GPU와 HBM(고대역폭메모리)을 결합하는 방식으로 구성된다. 여기에 EOPPP 기술을 적용하면 CPU와 HBM의 결합만으로도 AI 반도체를 만드는 것이 가능해진다.
이종열 교수는 "EOPPP 기반 CPU를 AI 반도체에 적용하는 경우, 기존과 달리 엔비디아의 개발 툴인 쿠다(CUDA)를 이용해 따로 프로그래밍할 필요가 없어진다"며 "연결할 칩 수가 줄기 때문에 공정 효율화는 물론, 애플리케이션 개발자의 편의성도 강화할 수 있다"고 말했다.
물론 전에 없던 새로운 프로세서를 정립하는 기술인 만큼, EOPPP의 상용화는 아직 걸음마 단계다. 컴파일러를 통한 기술 검증부터 관련 IP(설계자산) 라이브러리 강화 등 해결해야 할 과제들이 적지 않다.
그럼에도 엔비디아·AMD·인텔 등 해외 업체가 주도하던 고성능 시스템반도체 시장의 변화를 일으킬 수 있다는 점에서, EOPPP에 대한 검증 향방을 살펴볼 가치는 충분한 것으로 보인다.