
[데뷰23] AI 모델 효과적으로 개선하려면
[지디넷코리아]
"인공지능(AI) 모델은 완벽하지 않습니다. AI는 판단을 못 하거나, 무관한 데이터를 습득하기도 합니다. 또 꾸준히 가르쳐야 합니다. AI 모델을 효과적으로 개선하려면 해당 이슈를 잘 해결해야 합니다."
쏘카 박경호 AI리더와 정현희 매니저는 27일 서울 코엑스 그랜드볼룸에서 개최한 개발자 컨퍼런스 '네이버데뷰(DEVIEW) 2023'에서 AI 모델을 지속적으로 개선, 유지하기 위한 방법을 소개했다.
박경호 AI리더는 모델 이슈를 ▲판단 실패 ▲관계 없는 데이터 수집 ▲새 학습 추가 으로 나눠 설명했다.

박경호 AI리더는 AI 모델 판단 실패를 첫 번째 이슈로 봤다. 판단 실패란, 말 그대로 AI 모델이 잘못된 판단과 예측을 하는 경우다. 이럴 경우에는 AI 모델 안에 필요 없는 데이터들을 하나하나 제거해야 한다. 시간·비용이 많이 드는 작업이다.
박 AI리더는 시간과 비용을 줄이면서도 무관한 데이터를 효과적으로 제거할 방법을 설명했다. 관련 없는 데이터가 AI 모델에 들어가기 전 미리 차단하는 시스템을 설치하는 방법이다.
그는 "모델이 해당 데이터를 최종적인 타겟 테이블에 넣기 전에 'ODD 디텍터'로 거르면 된다"고 설명했다.
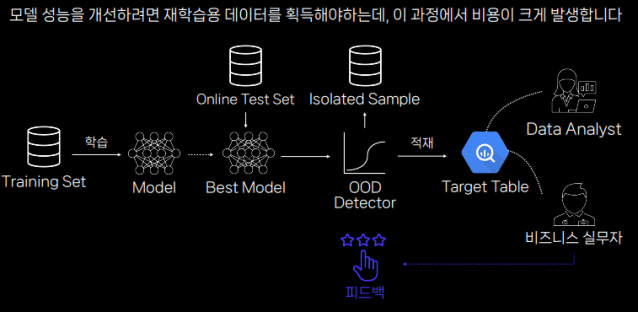
ODD 디텍터란 기존 데이터와는 다른 환경이나 문맥에서 생긴 무관한 데이터를 거르는 소프트웨어(SW) 도구를 의미한다. AI 예측 실패를 막기 위해 필요한 SW 도구다.
박 리더는 "ODD 디덱터가 거른 데이터는 AI 모델과 무관한 데이터이며, 모델 예측을 실패하게 하는 요인이다"고 말했다. 반면 ODD 디텍터를 통과한 데이터는 AI 모델과 조금이라도 연관있거나 데이터셋 분포에 포함된 데이터다. AI 모델이 잘 이해할 수 있는 데이터이기도 하다. 추론 기능도 좋다.
또한 그는 "이 디텍터를 통해 AI 추론 결과 퀄리티를 올릴 수 있다"며 "자동으로 데이터를 거를 수 있어서 개발자가 수동으로 샘플을 수정해야 하는 경우도 줄어든다"고 강조했다.
박 리더는 걸러진 데이터를 그냥 폐기하지 않는다고 했다. 이를 별도로 모아 추가 분석을 진행해야 한다는 입장이다. 그는 "AI 모델이 어떤 데이터를 주로 잘 이해하는지, 어떤 데이터를 낯설어하는지 알아야 한다"며 "차단된 데이터 샘플을 별도로 분석하면 AI 모델을 더 개선할 수 있다"고 덧붙였다.
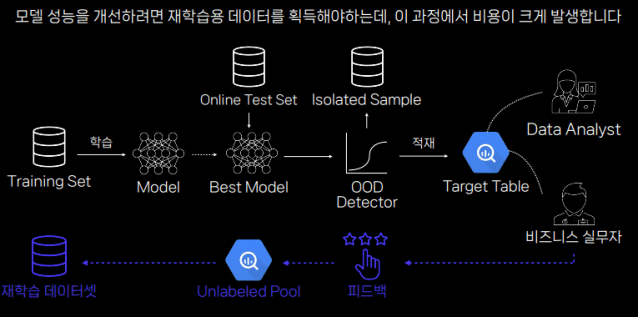
AI 모델을 꾸준히 향상할 방법이 또 있다. 바로 추론을 통한 데이터 수집이다.
일반적으로 실무자나 전문 유저들은 AI 모델에 추가로 필요한 샘플을 피드백 형식으로 요청한다. AI 개발자는 해당 피드백을 모델에 반영한다. 필요한 데이터를 모아 하나하나 레이블링한다.
박경호 리더는 "데이터 샘플이 몇만 개 들어있는 모델에 5~6개 피드백 샘플만 넣는다고 해서 재학습을 잘 할 수 없다"고 지적했다. AI 모델이 안정적인 추론을 하려면 샘플과 관련한 데이터를 추가로 찾아 레이블링해야 한다. 그러나 이 과정은 시간·비용이 많이 든다.
샘플과 비슷한 데이터만 끌어오는 '데이터 리트리버' 모듈을 통해 가능하다는 입장이다. 기존에는 레이블 되지(언레이블) 않은 데이터 풀에서 원하는 데이터가 나올 때까지 하나하나 찾아야 했다. 반면 데이터 리트리버 모듈은 필요한 샘플이 어떤 종류인지만 알면 언레이블된 데이터 풀에서 밀접한 데이터를 추린다.
박경호 리더는 "리트리버는 언레이블된 풀에서 타겟 데이터 후보군을 골라주는 역할을 한다"며 "레이블링하는 비용과 시간을 획기적으로 줄일 수 있어 재학습 데이터셋을 효율적으로 구축한다"고 강조했다.
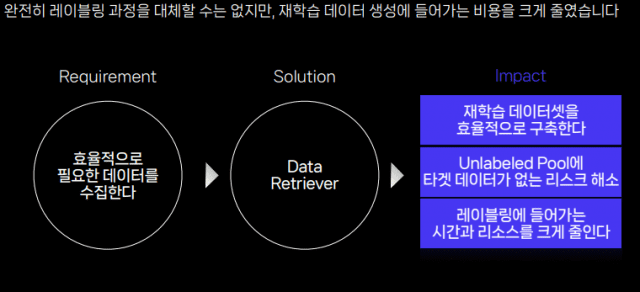
박경호 리더는 "물론 AI의 추론을 통해 이뤄지는 과정이라 100% 믿을 순 없다"고 말했다. 그는 "레이블링 담당자가 추가로 확인하는 과정을 거쳐야 한다"고도 덧붙였다.

AI 모델이 성장하려면 꾸준히 학습해야 한다. 정현희 매니저는 이를 '컨티뉴얼 학습법'을 통해 효과적으로 할 수 있다고 발표했다.
컨티뉴얼 학습법이란, 하나의 AI 모델을 조금씩 업그레이드하면서 여러 작업을 처리할 수 있도록 만드는 법이다. 사람이 정보를 습득하는 방식과 유사하다. 정 매니저는 AI 모델을
정 매니저는 "컨티뉴얼 학습법은 인간이 정보를 습득하는 방식과 유사"하다며 해당 학습법으로 훈련한 모델 성능을 소개했다.
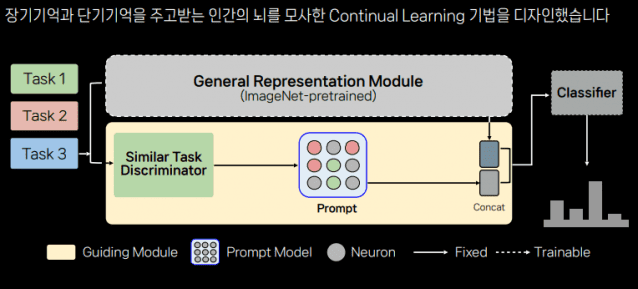
사람은 새 지식을 학습할 때마다 새 저장공간을 만들지 않는다. 계속 배우면서 정보를 쌓는 식이다. 정현희 매니저는 "마찬가지로 컨티뉴얼 학습법을 채택한 AI 모델은 별도로 새로운 저장 공간을 만들지 않고 훈련했다"고 했다.
사람 뇌는 단기기억과 장기기억을 따로 저장한다. 이를 주거니 받거니 하면서 지식을 축적한다. 정현희 매니저는 이를 AI 모델에도 적용했다고 설명했다. 그는 "반복 훈련(지식)으로 나온 결괏값은 장기기억으로 설정하고, 특정 테스크와 관련한 건 단기기억으로 입력하고 훈련했다"고 밝혔다.
정현희 매니저는 "이런 가정하에 AI 모델 학습 성능을 테스트했다"며 "결과적으로 기존 학습법 대비 높은 모델 성능을 달성했다"고 강조했다. 그는 "해당 실험 결과가 실제 환경에서 효용성이 있는지도 알아봐야 한다"며 "여러 모델과 비교 분석도 필요하다"고 덧붙였다.